
 This month’s TSQL Tuesday topic (follow Twitter hashtag #TSQL2sDay) is hosted by Michael J. Swart ( blog | Twitter ) and the topic is, “What are your thoughts on Database Indexes?”
This month’s TSQL Tuesday topic (follow Twitter hashtag #TSQL2sDay) is hosted by Michael J. Swart ( blog | Twitter ) and the topic is, “What are your thoughts on Database Indexes?”
One of the most powerful features of indexes is that they can provide a performance benefit without requiring a change to the underlying code. This is incredibly important in my world, as I work for a software company and when customers encounter performance issues, I cannot change code in an attempt to tune queries; but I can add indexes.
We had a customer issue in July where a customer found a particular query that took seven seconds to execute. The query was something like this:
{code}SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’;{/code}
And the Execution Plan looked like this:

(Note: I’m using the AdventureWorks database for this example, even though a RTRIM would likely never be used against LastName in the Person.Contact table because it’s a nvarchar data type. In my issue with the customer, the column was a char.)
I can hear the sighs now, many of you know what’s coming; but let’s step through trying to tune this with indexing.
First, if we check the indexes on the table, we see there is no index that leads with LastName: 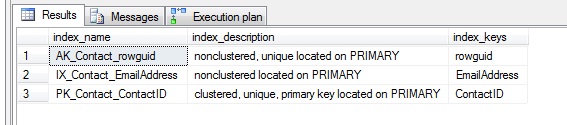
Let’s add an index on LastName:
{code}CREATE NONCLUSTERED INDEX IX_LastName ON Person.Contact(LastName);{/code}
Now let’s see what the Execution Plan looks like when we re-run our original query:
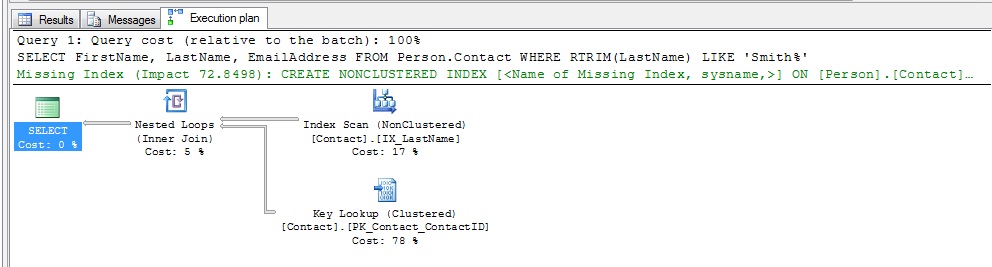
It’s better. We now have an Index Scan instead of Full Table Scan, and since the index is much narrower than the table, the IO should be much lower. But I want a seek on this query. The index I created isn’t a covering index, and I can see the Key Lookup to get the FirstName and EmailAddress from the Clustered Index. I know that querying only on LastName, or creating an index to cover all three columns will alleviate the Key Lookup, but it won’t affect the Index Scan. We can prove it by only selecting LastName (again, I could also create a covering index to test, but this is easier):
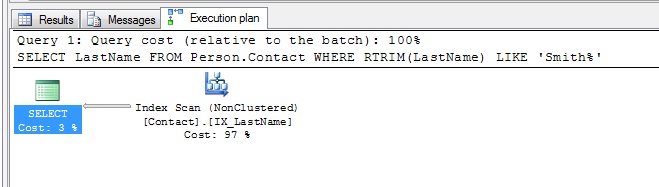
Still no seek, and the Key Lookup is gone as expected. What else can I modify? Yep…the function. Let’s remove the RTRIM and see what we get:
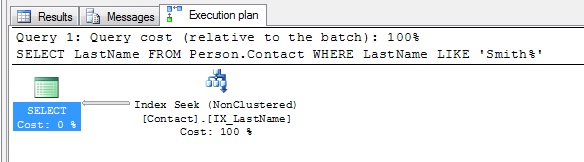
Fabulous, now I have the Index Seek I was so desperately seeking. I could drop the index I created and create a covering one to support the original three-column select, but that doesn’t solve the fact that I still have a function in the query. And as I stated earlier, I cannot modify the code. So what can I do?
What I haven’t told you is that this customer is running our software on Oracle. Don’t worry, I still love SQL Server best, but our application supports both platforms. In Oracle, I can create a Function Based Index to support this type of query. The syntax in Oracle , for our example, is:
{code}CREATE INDEX IX_LASTNAME_FUNCTION ON PERSON.CONTACT(RTRIM(LastName));{/code}
When we added this index to the customer database, the query time for the original query became sub-second.
But what if the customer had been running SQL Server? Does SQL Server allow a Function Based Index? It does not – you will find no reference in the CREATE INDEX documentation. The closest thing is a computed column in the table, using that function, with an index on that computed column. Let’s see how the computed column would work.
First, alter the table:
{code}ALTER TABLE Person.Contact ADD LastName_Computed AS RTRIM(LastName);{/code}
Second, create an index to support the query:
{code}CREATE NONCLUSTERED INDEX IX_LastName_Computed ON Person.Contact(LastName_Computed);{/code}
Now, at this point, I cannot just re-run my original query and expect it to use the new index on LastName_Computed, I have to change the column I am selecting and querying in my query:
{code}SELECT LastName_Computed FROM Person.Contact WHERE LastName_Computed LIKE ‘Smith%’;{/code}
If I do this, I get an index seek on LastName_Computed. But I’m back to square one because again, in my situation I actually don’t have the ability to change code. I can change the schema, so adding the column and the index would be ok, but the code would need to be altered to select from this column.
I would bet that when many of you saw this query, your first question was, “Why is there a RTRIM in the where clause?” It’s a good question, and one that I took to development. I’m still working to sort out why we have the RTRIM in there, but the good news is that it is only in the code for Oracle and we can add the index as a work-around for now.
And for the record, the rule-follower in me believes the plural of index should be written as indices, but because I never see it or hear it used anywhere, I always use indexes.
Clean up code:
{code}DROP INDEX Person.Contact.IX_Lastname;
DROP INDEX Person.Contact.IX_LastName_Computed;
ALTER TABLE Person.Contact DROP COLUMN LastName_Computed;{/code}
*Update: Follow up and additional information can be found in Seek and ye shall find.


This is one of the point I make in my sargability talk, like in this weeks’ #24hop.
And a Connect item at http://connect.microsoft.com/SQLServer/feedback/details/566418/indexes-on-expressions
Nice post, incidentally.
Thanks for the feedback! I will check out the connect item (I will miss your sargability talk, but will try to catch the re-run 🙂
I’m not actually doing the sargability talk at PASS. It got “Tentative” approval, but because I’m doing two sessions already, it’s not going to get used. I’m doing it at SQLBits on October 1 in the UK, and you can a recording of when I delivered it to the AppDev PASS Virtual Chapter at https://www.livemeeting.com/cc/usergroups/view?id=3J8NQ7
On SQL Server 2008 (10.0.2789):
SELECT LastName_Computed FROM Person.Contact WHERE RTRIM(LastName) LIKE ‘Smith%’;
and
SELECT FirstName, LastName, EmailAddress FROM Person.Contact WHERE RTRIM(LastName) LIKE ‘Smith%’;
…both result in an index seek (plus key lookup for the second example) on the indexed computed column.
There are still examples where the optimizer cannot perform the required expression matching, but support seems to be improving all the time.
Paul
Hi Paul,
I demonstrate a situation where it doesn’t work in my talk, such as trying to use:
convert(datetime,CONVERT(char(6),OrderDateTime,112)+’01’,112)
In this one, the Predicate (not Seek Predicate) comes out as:
CONVERT(datetime, CONVERT(char(6),[AdventureWorks].[dbo].[rf_SalesOrders].[OrderDateTime],112)+[@1],112)=CONVERT_IMPLICIT(datetime,[@2],0)
… and this means that it hasn’t recognised the benefit of the computed column at all.
Rob
Awesome post Erin, Thanks for contributing. I’m glad you’re a bold rule-breaker (go team indexes).
Paul-
This was in SQL 2008 R2? If so, Jeremiah Peschka saw similar behavior, with an index seek instead of the scan I was seeing in 2008 SP1. I am trying to find a R2 install to test myself (for the code in my post). I will let you know what I find. Thanks for testing and posting back!
Erin
Thanks Michael! And thanks again for hosting and compiling the final lists of posts.
Erin
Hi Erin,
Tested on SQL Server 2008 (not R2) version 10.0.2789 – SP1 CU9.
(enabled notification for comments this time!)
Paul
Rob,
The cause of that is auto-parameterization, I sent you some workarounds by email – including one that works without modifying the query 🙂
Paul
Paul-
I will test on my side to verify I’m seeing the same thing and then update my post or do a new one.
In that case, the optimizer recognizes that a column (LastName_Computed) with the function from the query exists and uses it, even though the query is against LastName. Right? That’s what you’re seeing?
Erin
Hey Erin,
Yes, that’s right. The following is exactly what I ran:
— From the blog
ALTER TABLE Person.Contact ADD LastName_Computed AS RTRIM(LastName);
CREATE NONCLUSTERED INDEX IX_LastName_Computed ON Person.Contact(LastName_Computed);
— Seeks on IX_LastName_Computed
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’;
— Seeks on IX_LastName_Computed
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’;
Cheers,
PAul
Paul-
Ok, I replicated. When I run:
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’
I do get the index seek on IX_LastName_Computed.
In my testing, I made the mistake of testing with this query:
SELECT LastName
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’
That query still does an index scan on IX_LastName.
Initially, I wondered why the second query wouldn’t use the same index. My first guess was reads. The first query (all three columns selected) is 228 reads. The second query(LastName only) takes only 57 reads…so I assume it’s doing the full scan because it’s fewer reads than the seek. If I try to force the first query with the regular index:
SELECT FirstName, LastName, EmailAddress
FROM Person.Contact WITH (INDEX(IX_LastName))
WHERE RTRIM(LastName) LIKE ‘Smith%’
It’s 282 reads. Then I start to wonder why that query is choosing the computed index, but I suppose that’s an optimizer thing that’s above my head.
Anyway, the entire point is that SQL Server WILL use the index on the computed column, if it’s that not the column in the WHERE clause. Agreed?
Erin
Erin,
Yes what you’re seeing is normal cost-based optimization. With both IX_LastName and IX_LastName_Computed available, the costing model produces a lower cost for the scan of IX_LastName, because it avoids a key lookup.
The ideal index for the SELECT LastName… query is:
CREATE NONCLUSTERED INDEX
IX_LastName_Computed
ON Person.Contact (LastName_Computed)
INCLUDE (LastName)
WITH (
DROP_EXISTING = ON,
FILLFACTOR = 100
);
BTW if you’d rather dig into this over email, you can reach me at SQLkiwi@gmail.com
Paul
Slightly off-topic, but contrary to what every Web search tells me, I am seeing some Index Seeks on indexed bit columns. Every SQL guru will tell you that indexing a bit column is rarely useful, but I have some evidence that in SQL 2008 (not R2), the query plan claims it’s doing Index Seek (nonclustered).
The distribution of the 0 and 1 values doesn’t seem to matter (I think they were 75% and 25% in one case, and searching for either 0 or 1, both cases used Index Seek).
Does this behavior match with what you expect, or am I out of bounds throwing this comment into your blog entry? 🙂
Thanks.
David Walker
Hi David-
I think that indexing a bit column *could* have value, IF one of the values is selective (e.g. 95% value for 0, 5% value for 1) or if you created a filtered index on the non-selective value. But it depends on that distribution AND the size of the table. In the case you described above, how wide is the table (bytes per row) and how many rows are in the table? Also, do you know how many pages are in the table, and the index you created for the bit column? With that information, we can try to predict the tipping point (where the optimizer will switch from using an index to scanning the table). If you have the execution plans and statistics io for your query, that’s also useful.
So what you’re seeing may or may not be unexpected…I’d need more info to tell you 🙂
Feel free to email me directly to continue the dialog. And just post back if you have problems emailing.
Thanks!
Erin
Thx for the post. I noticed same thing, but also discovered that when searches are directed at the computed column even though the column has an index and a seek is performed a key lookup is also conducted and thus the logical reads are a bit more.
Notice this only occurs when other columns outside of the “computed columns” are queried.
[quote name=”Daniel Adeniji”]Thx for the post. I noticed same thing, but also discovered that when searches are directed at the computed column even though the column has an index and a seek is performed a key lookup is also conducted and thus the logical reads are a bit more.
Notice this only occurs when other columns outside of the “computed columns” are queried.[/quote]
BTW, tbis is MS SQL Server 2005 – SP3
True. If you include columns in your select list which are not covered by the index, then SQL Server has to do a key lookup to get those columns from the underlying clustered index or heap. This will occur in 2005 or 2008. Thanks for the comment!