
When I was thinking up names for this blog, I had a hard time not using the name my husband uses for his fantasy baseball team: The Stellato Heels. It’s great, isn’t it? I can boast about how fabulous it is because I didn’t think of it. I had great visions for the logo. Just imagine a glamorous high heel with some sparklies and a splash of color. Unfortunately, I’m not one for heels (or sparklies if we’re being honest). Don’t get me wrong, I like shoes. I have a lot of pairs, but I don’t wear heels unless I’m pretty dressed up, and that only happens about twice a year. So, as much as I loved the name, it didn’t really represent me.
The name I chose in the end, The SQL Sequel, I loved for two reasons. First, I love movies. When I was a kid we had one of the first VCRs in the neighborhood, and my dad used to record movies on tape (usually three on a tape) that he numbered and labeled. Then he had this flip-top address book that listed each movie on the appropriate letter page, along with the tape number. The tapes were stored on shelves in alphabetical order. I now realize these were my first clustered and non-clustered indexes.
The second reason the blog title is very “me” is because I am never done with what I learn. There is always another detail to learn for any concept. I knew it wouldn’t take a long for a sequel blog post to come up, and I was right; this one’s the first.
In September’s TSQL Tuesday post I blogged about a non-sargable where clause, which forced a full index scan. My solution was to create a new computed column with the function, along with a non-clustered index, and use that. I wasn’t thrilled with that solution because I thought I then had to change my query to use the computed column in my where clause.
I was wrong.
If you read through the comments of that post, you’ll see the great exchange I had with Rob Farley ( blog | Twitter ) and Paul White ( blog | Twitter ). Paul is my new favorite Kiwi (why was I not following him on Twitter?) and he also did a quick review of this post for me (thank you Paul!). In my initial testing, after I created my computed column and its index, I re-ran the last query:
{code}SELECT LastName
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%'{/code}
And it did a full scan on the IX_LastName index:
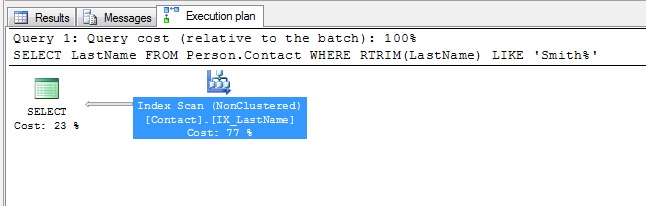
I didn’t test my original query, because I thought I knew what it would do. But Paul pointed out that if I ran my original query:
{code}SELECT FirstName, LastName, EmailAddress
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’;{/code}
it actually used the IX_LastName_Computed index:
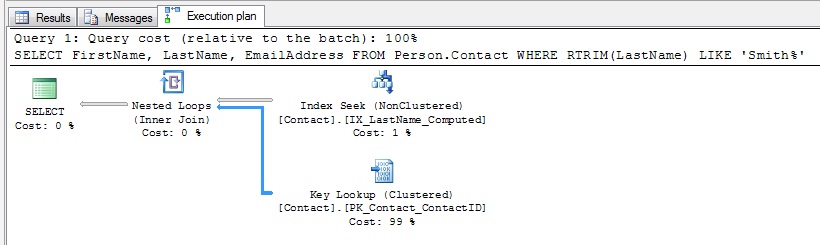
Those peeps that write the Optimizer code know what they’re doing. Even though I’m querying LastName in the where clause, the Optimizer knows the information I really need (because of the RTRIM) is in the IX_LastName_Computed index, and it seeks it. So why did my query with only LastName as the selected column use IX_LastName? It’s all about I/O.
The original query (all three columns selected) is 228 reads. The modified query (LastName only) takes only 57 reads; it’s doing the full scan because it’s fewer reads than the seek. If I try to force the first query with the regular index:
{code}SELECT FirstName, LastName, EmailAddress
FROM Person.Contact WITH (INDEX(IX_LastName))
WHERE RTRIM(LastName) LIKE ‘Smith%’;{/code}
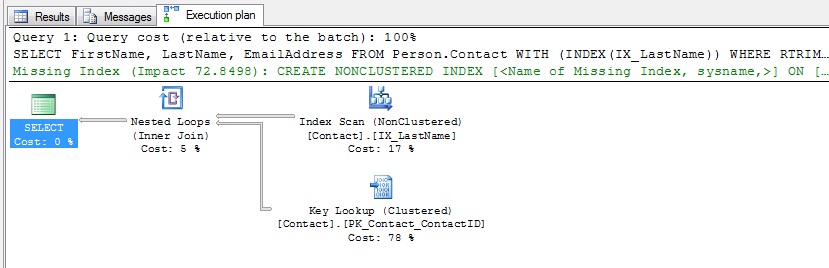
It’s 282 reads. To quote Paul,
“…what you’re seeing is normal cost-based optimization. With both IX_LastName and IX_LastName_Computed available, the costing model produces a lower cost for the scan of IX_LastName, because it avoids a key lookup.”
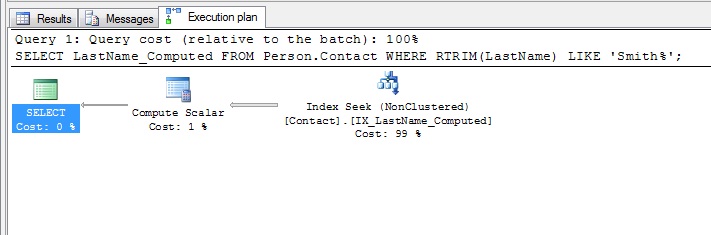
And as Paul also pointed out to me, this query:
{code}SELECT LastName_Computed
FROM Person.Contact
WHERE RTRIM(LastName) LIKE ‘Smith%’;{/code}
will also use the IX_LastName_Computed index:
Aside from learning more about the optimizer, the biggest thing that I took away from this is to try every permutation, even if you think you know what’s going to happen. I think you learn more when what you’re expecting doesn’t happen.
A huge thank you to Paul and Rob for their help in producing the first true SQL Sequel on my blog! I love that I am learning something new all the time. I am constantly reminded of how much I don’t know. Some days it frustrates me, other days I remember that it’s just life, and it’s about the journey, not the destination.


Hi Erin…
I like the title of your blog, and I especially like the logo.
Your story about your Dad’s video collection reminded me of something in my past as well.
When I was about 14, we moved to a new house, and I volunteered to catalog my Dad’s library of books (not realizing that he had dozens of boxes of extra books stored away in the garage that I hadn’t even known about).
I painstakingly typed up a card catalog for hundreds of books, putting the catalog in Title order and shelving the books in (Author,Title) order.
Like you, that was my first hands-on experience with CIX’s and NCIX’s. Could it have influenced my direction in life?
Who’s to say?
–Brad
P.S.: Stellato Heels… LOL
Brad-
That is a GREAT story! I used to love the card catalog at school, it was so organized, so predictable. You may be on to something with the influence it had in our lives 🙂
Thank you for your feedback and your comments. The first time my husband said Stellato Heels I laughed out loud, it kills me. It’s just too bad I don’t wear Manolos every day!
Erin
This is such an awesome post.
I love that you learned even more from your TSQL Tuesday post than you thought you did. There’s a lot of great stuff in both posts. Seems to me this is what it’s all about.
Kendra-
I completely agree, the extra bit I learn from every experience is exactly what it’s all about. It never ends. Kind of overwhelming and exhilarating at the same time!
Erin
Fantastic SQL Sequel, Erin. I agree with Kendra – this is a great example of why blogging is so rewarding. Loving your work.
Paul