
Every so often we hear from a customer who gets a variation of this message when trying to upgrade their database to a newer version of our application:
Msg 5074, Level 16, State 1, Line 1
The statistics ‘my_stats’ is dependent on column ‘column1’.
Msg 4922, Level 16, State 9, Line 1
ALTER TABLE ALTER COLUMN name failed because one or more objects access this column.
The issue is that the customer has created statistics manually on a column we are trying to alter as part of the upgrade process. This does not happen for statistics that were auto-created by the optimizer, as the engine drops those behind the scenes if you alter the column.
The first question I ask is “Who added the statistic and why?” Now, customers are permitted to create statistics manually if it will provide benefit, so no one is in violation of any agreement. But if there is a performance issue that a customer encountered and fixed independently, I want to know about it. It is possible that the problem is unique to their environment. But it is also possible they are the first customer to encounter it, and other customers will, and we need to be proactive about it.
The funny thing is that the customer inevitably states that they have no idea how the statistics came to exist. I know that *someone* must have created those statistics…but it usually remains an unsolved mystery.
In the end we provide a query to list all user-created statistics in the database, tell the customer to drop the statistic(s), and then they can recreate them after the upgrade. This gets a little tricky because I do not know from memory what columns, if any, might be altered as part of an upgrade. In addition, you do not have to drop user created statistics for every column that is altered. For example, you can have statistics on a varchar column and increase the length without dropping user created statistics. This is explained in more detail in the BOL entry for ALTER TABLE.
The code below steps through a demo of the issue I described, including a variation of the query to list user created statistics.
First create a table in one of your sandbox databases and add a clustered index:
CREATE TABLE dbo.titles ( name CHAR (500), releaseyear SMALLDATETIME, rating VARCHAR(5) ); CREATE CLUSTERED INDEX CI_ReleaseYear ON dbo.titles (releaseyear);
Add some data…
INSERT INTO dbo.titles (
name, releaseyear, rating
)
VALUES
('The Hangover', '2009-06-05 00:00:00', 'R'),
('The Hunt for Red October', '1990-03-02 00:00:00', 'PG'),
('Apollo 13', '1995-06-30 00:00:00', 'PG'),
('A Few Good Men', '1994-12-11 00:00:00', 'R'),
('The Natural', '1984-05-11 00:00:00', 'PG'),
('IronMan', '2008-05-02 00:00:00', 'PG-13'),
('The Incredibles', '2004-11-05 00:00:00', 'PG'),
('Apollo 13', '1995-06-30 00:00:00', 'PG'),
('The Truman Show', '1998-06-05 00:00:00', 'PG-13'),
('All The President''s Men', '1976-04-09 00:00:00', 'R');
Now let’s take a look to see what statistics currently exist:
sp_helpstats N'dbo.Titles', 'ALL'
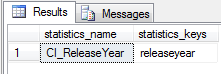
Great, we can see that we have one statistic for our clustered index.
Just for fun, we will force the optimizer to create statistics on a column for us, after we verify that AutoCreate Statistics is enabled:
/* verify auto-update statistics is enabled */ SELECT CASE WHEN is_auto_create_stats_on = 0 THEN 'Auto Create Stats Disabled' WHEN is_auto_create_stats_on = 1 THEN 'Auto Create Stats Enabled' END FROM sys.databases WHERE database_id = DB_ID() /* query to invoke creation of stats on rating column */ SELECT name, rating FROM dbo.titles WHERE rating = 'PG' GO /* verify new column statistic was created */ sp_helpstats N'dbo.Titles', 'ALL'
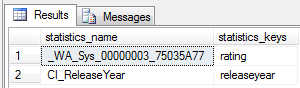
Note that statistics that start with _WA are ones created for you by the optimizer. If you really want to know how the statistic name is derived, check out Paul Randal’s post that explains it. All right, now we need to create a statistic manually:
CREATE STATISTICS us_name ON dbo.Titles (name) WITH FULLSCAN GO sp_helpstats N'dbo.Titles', 'ALL'
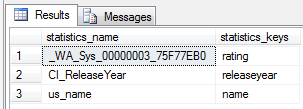
Success, we can see that it exists. Note, I use “us” as a prefix to denote user statistic, and I tend to always capture a 100% sample.
Now we are ready to alter our table…
ALTER TABLE dbo.Titles ALTER COLUMN name char (1000);
…and we get the lovely message:

Duly noted. At this point I like to check to see what user statistics exist in the entire database. For SQL Server 2005 onward, this is pretty easy:
SELECT st.name AS TableName, ss.name AS StatisticName FROM sys.stats ss JOIN sys.tables st ON ss.object_id=st.object_id WHERE ss.user_created = 1 ORDER BY st.name, ss.name;
Now I have some information, which is a good starting point, but as I said earlier I probably don’t need to drop every statistic. In this case, I need to drop it because I am modifying a column of char data type. It would be useful to see the data type of the column…
SELECT st.name AS TableName, ss.name AS StatisticName, sc.name AS ColumnName, t.name AS DataType, CASE when sc.max_length = -1 then 'varchar(max), nvarchar(max), varbinary(max) or xml' else CAST(sc.max_length AS varchar(10)) END AS ColumnLength FROM sys.stats ss JOIN sys.tables st ON ss.object_id=st.object_id JOIN sys.stats_columns ssc ON ss.stats_id=ssc.stats_id and st.object_id=ssc.object_id JOIN sys.columns sc ON ssc.column_id=sc.column_id and st.object_id=sc.object_id JOIN sys.types t ON sc.system_type_id=t.system_type_id WHERE ss.user_created = 1 ORDER BY t.name, st.name;
Now I have a better idea of what I might have to drop and then recreate after the ALTER completes. For our example, we can drop the statistic, and then successfully alter the column:
DROP STATISTICS dbo.Titles.us_name; ALTER TABLE dbo.Titles ALTER COLUMN name char (2000);
Again, if this column were a varchar, we would not encounter the same issue (feel free to modify the data type for the name column and run through the script again). Also, finding the user created statistics in SQL 2000 is not as easy. When I ran into this issue for a customer running SQL 2000, Jonathan Kehayias ( blog | @SQLPoolBoy ) and Amit Banerjee ( blog | @banerjeeamit ) provided options for how to get the information, and I ended up using the query below:
select so.name as TableName, si.name as StatisticName from sysindexes si join sysobjects so on si.id = so.id where si.status&0x40 = 0x40 and si.status&0x800000=0
Since we still have a fair number of customers running SQL 2000, this will come in handy. Thanks guys!


Excellent post, Erin… Great info!
I especially liked the link to Paul’s post on how the auto-created stats names are put together… I never knew that one before.
–Brad
Thanks Brad! Paul was actually here in that Cleveland that week, so I remember it well 🙂 Always a fun little piece of info to share,
Erin
When I run the first query you provided to find user created statistics, I get 224 rows with each StatisticName starting with “_dba_stat_”. Do you know if such statistics created by DTA could cause a problem with schema updates down the road?
Mark-
In my experience, statistics or indexes that start with _dba* are ones created by the DTA as hypothetical, and then were not removed by DTA for some reason (e.g. DTA was stopped abnormally). However, I suppose that you could have accepted DTA’s suggestions for statistics and left them with the default name.
When you update statistics for the table, are these statistics getting updated? If so, then I would expect them to have the same impact on schema updates as user-created statistics.
Lastly…assuming the stats that start with _dta are not hypothetical and are being used by the optimizer, 224 statistics for a table sounds a little high. Have you done any manual tuning, or are you relying on DTA?
Erin
Erin,
The 224 statistics are not for one table, they are for many tables. The table with the most statistics has 85. That table has 18 indexes and is the heart of our system. The next highest number of statistics for one table is 30 and they drop sharply from there.
I have a query to tell when the stats were last updated for each index, but I don’t know how to get the name of the stat that was updated, just the table and index name. How can I tell which stats are not getting updated?
I have a Maintenance Plan that updates all existing stats for all objects in all databases weekly, yet I do have quite a few indexes (all of which are NONCLUSTERED PK or CLUSTERED UK indexes) that show up with a null STATS_DATE when I run my “Last STATS_DATE for each index” query. Any idea why?
– Mark
The sys.stats.name column of your query is showing many stats named _dta_index_*, but none are named _dta_stat_*. The docs for sys.stats says “Every index will have a corresponding statistics row with the same name and ID (index_id = stats_id), but not every statistics row has a corresponding index.” How can i find out when stats have been updated that don’t correspond to an index? Or does the fact that a Statistics file has no corresponding index tell me that it is not needed. I would think that stats on a column, even if that column is not indexed, would still be useful to the optimizer under some circumstances.
Sorry, I mean that the sys.stats.name column of my “Last STATS_DATE for each index” query have no stats names _dta_stat_*.
Mark-
Ok, if the stats are name _dta_index* then they correspond to hypothetical indexes that were created by the DTA. If you run the query below, and change the table name of Sales.SalesOrderDetail to your table name, you should see when all stats for the table were last updated:
select
so.name as TableName,
ss.name as ‘Statistic’,
STATS_DATE(ss.object_id, ss.stats_id) as ‘Statistics Last Updated’,
case ss.auto_created
when 0 then ‘No’
when 1 then ‘Auto Created’
end as ‘AutoCreated?’,
case ss.user_created
when 0 then ‘No’
when 1 then ‘User created’
end as ‘UserCreated?’
from sys.stats ss
join sys.objects so on ss.object_id=so.object_id
where ss.object_id = OBJECT_ID(‘Sales.SalesOrderDetail’)
order by ss.name
Based on that output, you should be able to see whether the stats are getting updated (and if they are, then that tells me you’re either doing index rebuilds to update them, or you’re updating stats some other way.
If you have stats with no corresponding index, that does not meant that the statistic is not needed. Those stats may be autocreated (start with _WA) or manually created. The optimizer still utilizes that information, and I wouldn’t recommend arbitrarily deleting the statistic(s) until you dig into it a bit more.
Hope that helps!
Erin
Erin,
After doing some more digging, I found that all of the _dta_stat_* statistics that have not been updated by the maintenance plan are for tables with zero rows. This seems reasonable. Unfortunately, there doesn’t seem to be any way to determine which user-created statistics aren’t being used, but that’s veering off the topic.
Thanks for helping me learn more about this topic and inspiring me to dig into this deeper.
– Mark
Mark-
Even if you can’t determine if the statistics are being used, you can determine if the indexes are. If you have statistics that start with _dta_index, then you must have indexes that start with the same name. If so, you can check the sys.dm_db_index_usage_stats DMV to see if the indexes every show up there, and if so, how much they’re utilized. Kimberly Tripp has a great post on this (http://www.sqlskills.com/BLOGS/KIMBERLY/post/Spring-cleaning-your-indexes-Part-I.aspx).
Glad this has helped a bit!
Erin
I use this:
— This query finds indexes that are possible candidates for removal due to non-use.
— Note that this is based on database statistics that are cleared when:
— SQL Server is restarted
— The database is detached/attached
— The database is restored.
SELECT s.name [Schema],
o.name [Table],
si.[name] [Index],
us.user_updates,
i.is_disabled
FROM sys.indexes i
JOIN sys.objects o ON i.object_id = o.object_id
JOIN sys.schemas s ON o.schema_id = s.schema_id
LEFT JOIN sys.dm_db_index_usage_stats us ON us.object_id = i.object_id AND us.index_id = i.index_id
LEFT JOIN sysindexes si ON us.[object_id] = si.id AND us.index_id = si.indid
WHERE si.[name] IS NOT NULL
AND o.type = ‘U’
AND us.user_lookups = 0
AND us.user_scans = 0
AND us.user_seeks = 0
AND i.is_primary_key = 0
AND i.is_unique_constraint = 0
Very cool post, Erin! This is something that isn’t usually mentioned when discussing creating statistics!
Great Post Erin, I started reading some of the articles on your blog, good stuff very detailed explanations. I wanted to ask you what plugin do use for code highlighting ? Its very snazy lol.
Thanks Kendra 🙂 I have a whole bunch of stuff to explore with statistics, glad this was somewhat useful/informative (one of those things where it is to me, just never know if it is to anyone else!).
E
Hi David-
Thanks for your comments! The plugin is named CodeCitation (for Joomla). Nothing too crazy 🙂
Erin
Hi there,
Was researching STATISTICS this morning, found this blog post via Google, and found it extremely insightful. Wound up rolling my own query, based on yours and what was found in the comments, to add to my toolbox. Never knew about the STATS_DATE() function, which I discovered here too.
Just wanted to say thank you for the great post!
Andy
Hi Andy-
I am glad that you found the information useful and were able to expand upon the queries here. Thanks for commenting!
Erin