
I worked on a very bizarre customer issue today that I thought I would blog about. I’m curious to see what thoughts people have. I need a new perspective on it since I can’t seem to figure out what to investigate next. Here’s the setup…
The problem was described as a search in one area of our application returned less data than expected, and a search in a different area of the application returned the proper amount of data.
My immediate thought was corruption. I have seen this one other time, where rows existed in the table, and corresponding rows existed in one nonclustered index (IDX1) for the table, but not in the other nonclustered index (IDX2) for the table. In that case, a query that used IDX1 or required a full scan of the table would find the rows, but a query that used IDX2 would not.
This was not the case today. I ran DBCC CHECKDB on the database, everything came back fine. I then dug into the query. I have provided the code for the two involved tables and relevant indexes below. Please note that this is pseudo-code, I am not recreating the exact tables from the customer environment because of confidentiality agreements. Names have been changes to protect the innocent…
{code}
create table dbo.titles (
TitleID int,
name varchar (1000),
releaseyear smalldatetime,
rating varchar(5),
ListID int,
moviestatus int,
runtime small int,
countryID int,
languageID int,
budget int
)
create nonclustered index IDX_titles on dbo.titles (ListID, TitleID, moviestatus)
create table dbo.listings (
ListID int,
ListName varchar(250),
col3 int,
col4 int,
col5 int,
col6 int,
col7 int,
col9 int,
col10 int
)
— yes, I got tired of thinking up pretend column names after a while
create nonclustered index IDX_listings on dbo.listings (ListID)
{/code}
The titles table had about 500,000 rows in it, and stats had been updated on March 11 (four days ago) with 100% sample. The listings table had 250 rows in it, and stats had also been updated with 100% sample on March 11.
When I would run the query below, I would get two rows returned.
{code}
select t.TitleID, t.name, t.releaseyear, t.rating, t.ListID, t.moviestatus,
t.runtime, t.countryID, t.languageID, t.budget, l.ListName
from dbo.titles t
join dbo.listings l on t.ListID = l.ListID
where t.releaseyear between ‘2010-05-01’ and ‘2010-05-31’
and (t.ListID = 1 or t.ListID = 2 or t.ListID = 3
or t.ListID = 4 or t.ListID = 5 or t.ListID = 6
or t.ListID = 7 or t.ListID = 8 or t.ListID = 9
or t.ListID = 10 or t.ListID = 11 or t.ListID = 12
or t.ListID = 13 or t.ListID = 14 or t.ListID = 15
or t.ListID = 16 or t.ListID = 17 or t.ListID = 18)
and t.moviestatus = 1
{/code}
If I removed the join to listings, and the display of the listings.ListName column, all the correct rows would return. The customer is running SQL 2000 SP4, and this was the query plan:
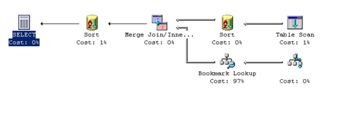
Column statistics existed for the ListID column. Even though I didn’t think it would matter, I dropped them to make sure. No change. Then I decided to drop the IDX_listings index. All the proper rows returned, and my query plan changed to:
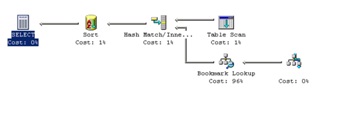
So I’m stumped. I can see that the operator changes from a Merge Join to a Hash Join. In both cases, the optimizer does a table scan of listings. In both cases, there are 240-some rows that come out from that full scan (you can’t see it in the screen shot, but trust me here). In both cases, there are 258 rows that come out of the seek on IDX_titles (that’s the bottom-right seek) and the bookmark lookup. Somehow, in the Merge Join, those 258 rows go down to 2…but in the Hash Join, all 258 come out.
I have no idea what’s going on. Part of me hopes I’m missing something obvious, part of me wonders if it’s a bug. I will post back when/if I get more information…


I assume it came in when you anonymised the SQL, but you do have two “t.ListID = 3” clauses, the second where I’d expect the ListID=6 clause to be.
But if dropping an index changes the query result, it stinks of a bug to me. Is it a particular ListId that gets lost ?
Gary-
You’re correct, I scrubbed the data and made a mistake in the query, I will fix it!
But yes, dropping an index, NOT EVEN USED IN THE ORIGINAL QUERY PLAN, changes the query plan and returns all the rows. What’s interesting is that it’s a specific ListID that shows up (e.g. 10). And then if I comment that ListID out, the results change and I rows for a different ListID (e.g. 9). There are almost 200 ListIDs in the actual query.
Thanks for the comment!
Erin
Erin,
Not sure if this is linked to your issue, but I’ve seen merge joins being affected by non-clus idxs that appear to be irrelevant.
On close inspection, any NC idx contains the clus key, so if the merge join needs the clust key, it will use the NC idx because it is smaller in size.
John-
Thank you for the suggestion. In this case, the underlying table was actually a heap…no clustered index. But again, in the case where not all the data was returned, the nonclustered index was not even used in the query plan. It did a table scan either way. Thank you for the comment, I am still waiting to see if I can upgrade the database to 2005 or higher and check behavior!
Erin
I wonder if this is an example of “when an unused index isn’t an unused index.” Rob Farley has a great chapter in SQL Server MVP Deep Dives about this. Indexes that don’t actually appear in the query plan are still being used by the optimizer, and dropping them affects the plan. A merge join needs to sort the data first, and since you have the query on that column, perhaps the optimizer is using the index? Doesn’t really explain why you only get 2 rows, but it might explain why dropping the seemingly unused index affects the plan.
Colleen-
Thanks for the suggestion! I just went through the Deep Dives book a couple weeks ago and marked all the chapters I want to read. There were a lot…and I just realized that I have it on my ereader, so will look it up. Again, still hoping to get the DB so I can dig into more, will keep you posted. Thanks!
Erin
Hi Colleen,
Yes, this is definitely a case of the unique index influencing the plan without being used. In this case, the index tells the Query Optimizer that each title will only match a single list, meaning that the Merge Join becomes more feasible. Without it, a Hash Match fits better.
I had a similar issue to this with a join across a relationship table, and after a tremendous amount of confusion (I’m more of a developer then a DBA) i eventually tracked it down to a NC index which wasn’t being shown in the execution plan and had no fields in the query. SQL works in mysterious ways.
Good Luck !
Your information Helped me Thanks you Much